Aurora Global Failovers
As part of an overwhelming stampede to migrate to the cloud, we are looking at using AWS RDS Aurora MySQL as a platform for some of our database clusters. Lots of people have lots of opinions about Aurora, some of them are probably justified and some probably not.
I was interested in testing the high availability and disaster recovery capabilities of Aurora. To be specific, I am testing Aurora v2 (though I expect v3 to work the same). I am also specifically testing Aurora Global databases
Aurora Global Clusters
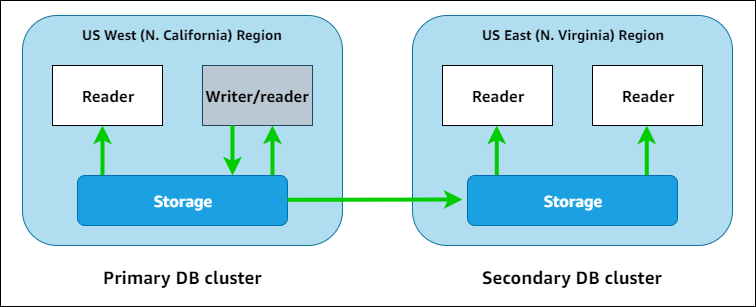
Aurora global databases are relatively simple to understand. Perhaps the best way is to describe it in the order in which you would construct it:
- Create your first regional cluster
- Create a global cluster from the first cluster
- Create replica clusters in other regions
Using Aurora global databases, User Guide for Aurora, AWS Documentation
Only one cluster can take writes at a time, and it is designated as the Primary cluster. The other cluster(s) are considered Secondary. Replication across region is done by the Storage layer and does not use standard MySQL replication.
Aurora Endpoints
Another important concept to understand is Aurora endpoints. Each cluster (in each region) has two default endpoints, a writer and a reader. The writer points to the currently primary writer instance and the reader points to all the reader instance(s) as you might expect. These endpoints are how your client would connect to the Aurora cluster and they automatically follow when instance roles changes, for example if Writer instance failed over to another in-region.
Each instance in the cluster also have their own direct endpoints, but use of these is not recommended since instance roles can change automatically.
In global clusters, endpoints still exist for each regional cluster. There is no concept of a global endpoint. Whichever cluster is the Primary has it’s Writer endpoint active. Secondary cluster’s have inactive Writer endpoints. To be specific, the endpoint on a secondary cluster has the Inactive status and the name cannot be resolved in DNS.
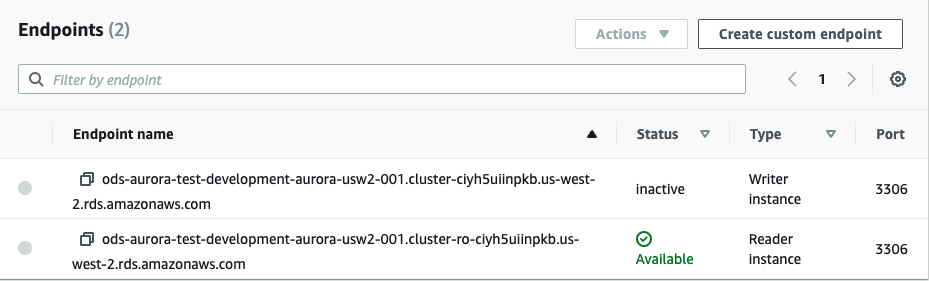
The writer endpoint is inactive in this secondary cluster
Ergo, the application must be aware of the endpoints in it’s deployment region. If the application is active in the non-primary Aurora region, it must somehow be aware of the endpoint in the Primary region or else not allow writes to the Aurora cluster. To be fair, there is an Aurora feature for Global Database Write forwarding that I have not experimented much with yet.
Planned Failover (aka Switchover)
Now that we have our shiny global cluster, let’s test failover! AWS calls this planned failover, though hopefully there isn’t much failure involved. Our goal is to safely change which cluster is primary without any dataloss and (hopefully) not a lot of application downtime.
This action can be taken from the AWS console with the ‘Fail over global database’ action on the Global database object, or else via the AWS rds CLI. Anyone who has done mysql primary switchovers ever should be familiar with the basic steps here:
- Set the old primary read-only
- Wait for replication to catch up
- Set the new primary read-write
Aurora is no exception, but there are a few additional steps. Because the new primary cluster’s writer endpoint is Inactive, it must be made active.
To test this, I connect a sysbench client to my primary cluster’s endpoint. Because there is no global endpoint, I have to pay attention to when the secondary cluster’s endpoint becomes available in DNS so I can reconnect my client to it instead. However, I have discovered that
Here is a representative sample of the timings of my operations:
| Time | Action / Event |
|---|---|
| 00:00 | Failover started |
| 02:19 | Writes cease in primary |
| 02:38 | Reads case on primary endpoint |
| 05:05 | Writes start on new primary cluster’s instance endpoint |
| 14:19 | The writer endpoint resolves in DNS |
From these timings, we can see clearly that the global failover operation is really supposed to finish around the 5 minute mark (after approximately 3 minutes of write downtime). Around this time, I can see the AWS console indicating that the new primary cluster’s writer endpoint indicates it is in the Available state, yet it does not resolve in DNS.
I have tested this many times, and to be fair it is not always this slow. I have observed the writer endpoint resolving in DNS much sooner than it did in my example here. I believe this is an AWS bug and AWS claims they will be fixing it soon.
Unplanned Failover
Amazon’s unplanned failover documentation is pretty interesting in the sense that they explicitly tell you not to use the failover button that you use for Planned failovers. Instead the steps can be summarized as such:
- Stop writing to your primary db (assuming their primary region is available enough that you can reach your application).
- Pick your target cluster to failover to
- Remove the target cluster from the global database
- Start writing to the new target cluster.
Step 3 effectively splits the target cluster such that you now have two database clusters. Depending on the severity of the AWS region outage, you may or may not be able to do any of the following:
- See if your primary cluster is up at all and taking writes
- Take some kind of action to ensure said primary cluster is not taking writes any more
- Execute any kind of reasonable STONITH/fencing procedures.
Based on the fact that AWS recommends against using it, it also that the “Failover” action for global databases is not trustworthy enough to even attempt to execute in the event of a primary region failure and so you have to take an alternative process in the event of a true failure. Personally, I’d prefer if something at least tried to execute the proper failover steps in case the outage is intermittent enough to occasionally be able to reach the region/cluster experiencing the problem.
As far as the observed time to execute an Unplanned failover, detaching the secondary cluster is a relatively fast operation. In that situation, nothing is setting the primary cluster read-only nor waiting for replication lag to catch up (at least in the sense that it can confirm all writes from the old primary have made it to the new). However, the same DNS propogation issue exists in this scenario that will delay the availability of the writer endpoint. Therefore, once this process is executed, I estimate it takes around 2-14 minutes or 2-4 minutes once the bug is fixed.
What AWS states about Failover
In short, the manual seems to acknowledge that “minutes” is to be expected:
While related marketing content seems to paint a rosier picture:
If you find any other public statements, I’d be happy to hear about them!